Different contexts can give different meanings to code and data. For instance, in computer architecture, code and data are just bytes stored in memory. In programming, code is a set of instructions or statements that operate on data as input. These definitions are accurate but not fixed. When we do high-performance programming, we can optimize our code and data by changing how we define them. This blog illustrates a small example of how code and data are interrelated.
Background
SpMV is an operation that multiplies a sparse matrix A with a dense vector x and stores the result in a dense vector y. A sparse matrix is a matrix that has mostly zero elements. To save space, we only store the nonzero elements of a sparse matrix. A common way to do this is using the triplet format. In this format, we use three arrays: row and col to store the coordinates of each nonzero element, and val to store the corresponding values. Figure 1 shows an example of the triplet format for matrix A. The coordinates of the nonzero elements are called the sparsity pattern, as shown by the row and col arrays in Figure 1b.
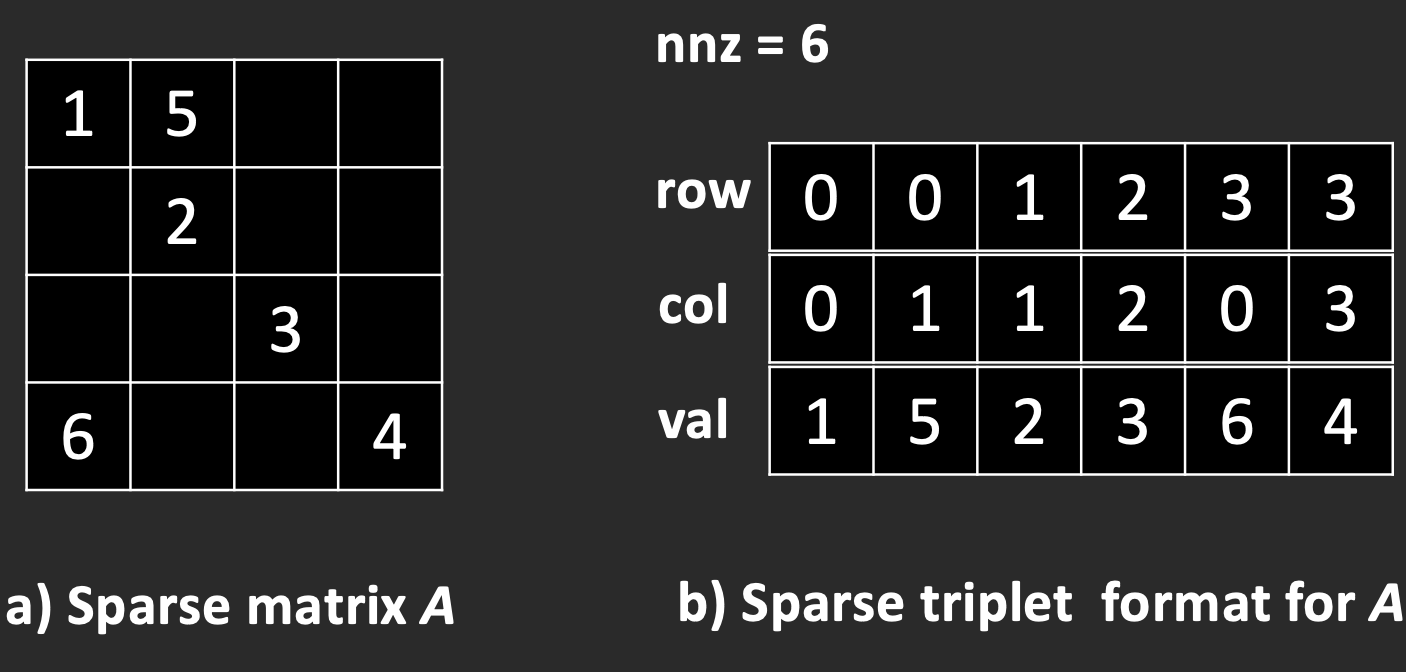
Code vs. Data.
Figure 2 shows matrix A and three different codes for the SpMV operation on it. Each code makes a different assumption about how code and data are defined. The code in Figure 2a assumes that both the sparsity pattern and the values of the matrix can change. However, in some computer simulations, the sparsity pattern of the matrix, given by the row and col arrays, is fixed and known at compile-time. The code in Figure 2b reflects this assumption. The compile-time information can be even more extensive in sparse neural networks, where the weight matrices are constant. The code in Figure 2c incorporates the values of A as part of the code. These codes illustrate how different definitions of code and data can affect the SpMV operation. This information can be used to optimize the code in various ways, such as reordering operations or using vectorization techniques. How to best exploit this information for performance improvement is an open research problem.
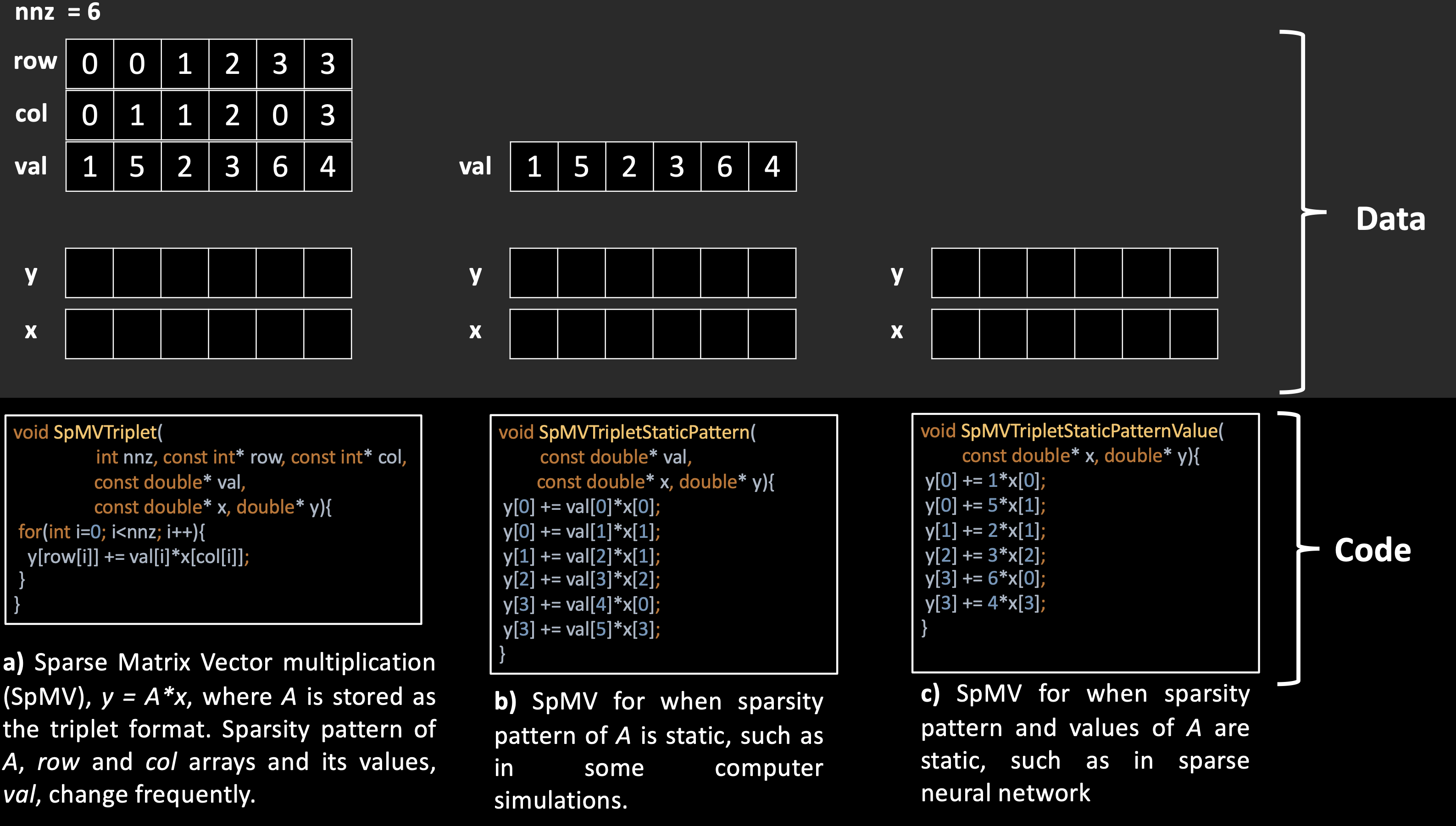
Code and data are usually different in programming, but we can treat any static information as code to make the program faster.